Azure machine learning pipelines are workflows of executable steps that enable users to complete Machine Learning workflows. Executable steps in azure pipelines include data import, transformation, feature engineering, model training, model optimisation, deployment etc.
Benefits of Pipeline:
- Multiple teams can own and iterate on individual steps which increases collaboration.
- By dividing execution into distinct steps, you can configure individual compute targets and thus provide parallel execution.
- Running in pipelines improves execution speed.
- Pipelines provide cost improvements.
- You can run and scale steps individually on different compute targets.
- The modularity of code allows great reusability.
Creating a pipeline in Azure
We can create a pipeline either by using Machine learning Designer or by using python programming
Creating pipeline using Python
1. Loading the workspace configuration
from azureml.core import Workspace
ws = Workspace.from_config()
2. Creating training cluster as a compute target to execute our pipeline step
from azureml.core.compute import ComputeTarget, AmlCompute
compute_config = AmlCompute.provisioning_configuration(
vm_size='STANDARD_D2_V2', max_nodes=4)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
cpu_cluster.wait_for_completion(show_output=True)
3. Defining estimator which provides required configuration for a target ML framework:
from azureml.train.estimator import Estimator
estimator = Estimator(entry_script='train.py',
compute_target=cpu_cluster, conda_packages=['tensorflow'])
4. Configuring the estimator step
from azureml.pipeline.steps import EstimatorStep
step = EstimatorStep(name="CNN_Train",
estimator=estimator, compute_target=cpu_cluster)
5. Defining and executing a pipeline :
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(ws, steps=[step])
Pipeline is defined simply through a series of steps and is linked to a workspace.
6. Validating pipeline to check
7. All steps are validated. We can now submit it as an experiment to workspace.
from azureml.core import Experiment
exp = Experiment(ws, "simple-pipeline")
run = exp.submit(pipeline)
run.wait_for_completion(show_output=True)
Creating pipeline using ML Designer
We have covered pipeline creation using Azure Machine Learning Designer in another article in detail.
Databricks is a cloud-based data engineering tool used for data transformation and data exploration through machine learning models. Azure Databricks is Microsoft Azure Platform’s implementation of Databricks.
Evolution of Databirkcs :
A short timeline of evolution of technology will give us an overview of the underlying stack.
2003: Google released Google File system papers in 2003.
2004: This was followed up in 2004 by Google MapReduce Papers. It takes a load of analytics work and distributes it across cheap compute instances.
2006: This led to Apache Hadoop creation in 2006. Apache Hadoop had a problem where it was doing a lot of functions which would cost hard disk input outputs.
2012: Matei started Spark project which built on Apache Hadoop and did a lot of the compute calculations in Memory.
2013: Spark was donated to Apache foundation by Matei. Matei & his Berkley colleagues founded Databricks. The platform provides a management layer over Apache Spark functions including the following :
- Spark providing Map Reduce in Memory
- DataFrames allow you to write Map Reduce for you. You can also write SQL statements which are then compiled into DataFrames call which can then do Map Reduce.
- Graph API
- Stream API
- Machine Learning
Databricks Implementations:
Since Databricks is a 3rd party tool. All major cloud platforms have their own implementation of Databricks. Google Cloud, Amazon AWS and Microsoft Azure are major Databricks providers.

Azure Databricks Environments:
Azure Databircks offers 3 environments for developing data intensive applications.

Azure Databricks SQL
It provides an easy-to-use platform for analyst who want to
- Run SQL queries on their data lake.
- Create multiple visualization types to explore query results
- Build and share dashboards
Azure Databricks Data Science & Engineering
Provides an interactive workspace for
- Enabling collaboration between data engineer, data scientists and machine learning engineers.
- Data (raw or structured) is ingested into Azure Data Factory in batches or streamed using Apache Kafka, Event Hub or IOT hub. This data lands in either Blog storage or Data Lake storage.
- Reads data from multiple data sources and turns them into insights.
Azure Databricks Machine Learning
Provides managed services for
- Experiment tracking
- Model Training
- Feature Development and Management
- Feature and model serving
Databricks Clusters
Types of Clusters
There are two types of clusters:
All-purpose clusters
Typically, used to run notebooks. They remain active until you terminate them.
Job clusters
They run when you create a job. They are terminated after the job is completed.
Creating a Cluster
Creating a cluster is necessary for getting started with data bricks.

Databricks Notebooks
After creating the workspace in first step, we can now create a notebook to execute our functions. This can be done via UI or CLI.
Clicking on Create -> Notebook is all there is to creating a notebook. Choose language and Cluster and finally click on the create button.
Databricks Cluster Navigation
Clicking on Clusters leads us to this helpful interface which gives us the following options :

Configuration
Lists the basic configuration of the cluster which we used to build this cluster.
Notebooks
Notbooks lists all the notebooks available in the cluster.

Libraries
Libraries interface allows us to attach appropriate SDK package to the cluster for our use cases.

Event Log
Gives a complete log of events in clusters.

Spark UI
This is the holy grail of all the sparks jobs which are actually running under the databricks shell.

Driver Logs
Driver logs gives detailed log of Sparks events.

Metrics
Metrics interface opens a separate application called Ganglia UI.

Apps
Apps gives an option to configure R studio

PowerBI provides a handful of features for building robust data models. Here are a few concepts to begin modeling data in PowerBI :
Fact tables & Dimensions tables:
In its simplest form, a data model design will consist of the following:
Fact table:
Also known as primary table. This table contains numeric data which we want to aggregate and analyze. It’s the primary table in a schema and has foreign keys to link it with dimension tables/
Dimension tables:
Also known as a lookup table. This table contains descriptive data. This descriptive data is primarily text data used to slice and dice the data available in primary tables.
Measures in PowerBI :
Measure In Power BI is an expression which outputs a scalar value. There are two classifications of measures in PowerBI
Implicit Measures:
Any column value can be summarized by a report visualization. This is referred to as an implicit measure. In other words, it’s the default summarization available for which you do not have to write a DAX query.
Explicit Measures:
Explicit measures on the other hand are those which require DAX calculation to query the underlying data model.
Generally, dimension tables contain a relatively small number of rows. Fact tables on the other hand can contain very large numbers of rows and continue to grow over time.
Relationships:
Once you have imported some data, the next step is to build a relationship between the tables. Relationship can be defined by either
1. Going to the Model view from Left Side Ribbon

2. Or, from Modeling -> Manage relationships

Purpose of Relationship:
Relationships decide how the filters applied on one column of the table will propagate to the other model tables. If a table is disconnected (does not have any relation to other tables), any filter applied on other tables will not propagate to the disconnected table. There are certain attributes of relations that determine the propagation of filters.
Relationship Keys:
The column on the basis of which relationship is established determines the link for propagating filters. To build a relationship, you need to determine which column will be the primary key and which one will be foreign key. Once the columns are determined, you can drag and drop the columns from either of the tables. PowerBI will prompt a dialog pop-up to confirm the keys.

In this example, we are creating a relationship between Date & Week Start Date.
Relationship Cardinality:
Cardinality defines what type of relationship exists between the tables; it can be:
1 to 1:
The column of the table on both sides has only one instance of the value.
1 to Many:
The column of the table on one side of the relationship is usually dimension table. It has only one instance of a value. This usually is the primary key. The table on many sides is usually a fact table and can have many instances of value.
Many to 1:
Many to one is inverse of the above with same logic. Just the direction is reversed.
Many to Many:
Many to Many relationships remove the need for unique values in tables. It removes the need to create bridging tables for establishing relationships.
In powerBi , it appears like this:

Relationship Direction:
Under the heading cross-filter direction, powerBI allows you to configure two types of directions

Single Cross Filter Direction:
Single cross filter direction would mean that relationship will only propagate in single direction. E.g., if a single cross filter direction is chosen in a 1 to Many relationships, filter will only execute when we filter from 1 side of the table.
Double Cross Filter Direction:
A double cross filter, as the name suggests, propagates filters from both directions. E.g., if a double cross filter direction is selected in a 1 to Many relationships, filter will execute from 1 side of the table as well as from the many sides of the table.
Cross filter options vary by cardinality. The following combinations are possible in PowerBI
| Cardinality type |
Cross filter options |
| One-to-many (or Many-to-one) |
Single
Both |
| One-to-one |
Both |
| Many-to-many |
Single (Table1 to Table2)
Single (Table2 to Table1)
Both |
PowerBI can support any schema arrangement. Here I cover the two most used ones
Commonly Used Schemas
Commonly used schemas in in PowerBI are:
Star Schema:
A star schema has a single FACT table which connects to multiple DIMENSION tables.
Cardinality: The cardinality between DIMENSION and FACT table in a star schema is 1 to Many.

Snowflake Schema:
Snowflake schema is a variant of STAR schema in which you have dimension tables that are related to other dimension tables in a chain. When possible, you should flatten these dimension tables to create a single table.
Cardinality: The cardinality between DIMENSION and FACT table in a snowflake schema is 1 to Many.
Comparison between Star & Snowflake Schema
| Star Schema |
Snowflake Schema |
| Simplest data model |
Relative Complex model |
| Hierarchies for the dimensions are stored in the dimensional table. |
Hierarchies are divided into separate tables. |
| It contains a fact table surrounded by dimension tables. |
It also contains one fact table surrounded by dimension tables. However, these dimension tables are in turn surrounded by other dimension tables. |
| Only a single join creates the relationship between the fact table and any dimension tables. |
A snowflake schema requires joins to fetch the data. |
| Denormalized Data structure |
Normalized Data Structure. |
| Data redundancy is high |
Data redundancy is low |
Python Dictionary
A dictionary in Python is a data structure to store data in Key: value format. There are several similarities between python lists and dictionaries, however, they differ in how their elements are accessed. List elements are ordered and are accessed by numerical index, dictionary’s items on the other hand are unordered and are accessed by key.
Each individual data point in a dictionary is called an item. It’s separated by a comma, An example dictionary in python would look like below.
dictionary {
'key': 'value',
'key2' :'value2'
}
Key Properties of Python Dictionary
A python dictionary has the following key properties
Ordered
Dictionaries are ordered. What it means is that order of the items within a dictionary is fixed. And that order will not change. Dictionaries are ordered from python version 3.7 onwards. In python version 3.6 and prior, dictionaries are unordered.
Changeable
Dictionaries are changeable. What it means is that we can add, remove items from the dictionaries after they have been created.
Duplicates are not allowed
Dictionaries do not allow duplicate keys. Any duplicate key will be overwritten by the later key.
Melbourne = {
'Area': '9,993 sq.km',
'Population' :'4,963,349',
2021 :'impacted by covid',
2021 :'Year of coffee'
}
This will print 2021 as ‘Year of coffee”, overwriting the previous value of the key.
Creating Dictionary in Python
Empty dictionary using {}
We can create an empty dictionary in python using the {} operator.
# Creating an empty dictionary
Melbourne = {}
Dictionary with items
We can also create a dictionary by specifying any items list separated by commas.
#Creating dictionary with items
Melbourne = {
'Area': '9,993 sq.km',
'Population' :'4,963,349',
2021 :'impacted by covid'
}
Notice the if the key is text, we have to include it in quotes. If it’s a numeric value, it does not need to be in quotes.
Dictionary with dict()
We can also use dict() function in python to create a dictionary.
Melbourne = dict({
'Area': '9,993 sq.km',
'Population' :'4,963,349',
2021 :'impacted by covid'
})
Accessing Dictionary Items
Python dictionaries provide a few functions to access both keys and values of dictionary items.
Accessing All Key:Value items using .items()
dictionary.items() function gives a list of all key-value pairs in the dictionary.
Melbourne = dict({
'Area': '9,993 sq.km',
'Population' :'4,963,349',
2021 :'impacted by covid'
})
result = Melbourne.items()
print(result)
dict_items([('Area', '9,993 sq.km'), ('Population', '4,963,349'), (2021, 'impacted by covid')])
Accessing Keys Only using .keys()
.keys() function is used to get only the keys of all items. If we replace the .items() function with .keys() function in the code above. It will only return keys this time.
result = Melbourne.keys()
print(result)
dict_keys(['Area', 'Population', 2021])
Accessing Item Values
There are two main functions for accessing item values
Using []
We can access specific dictionary item by providing it’s key either explicitly or in a loop. In the example below, I am providing an explicit key.
Using .get()
Another way of accessing an item value is by using dictionary.get() function
print(Melbourne.get('Area'))
Removing items
Python provides two main function for removing either the key or the key:value pair from the dictionary.
Removing item using .pop()
dictionary.pop() function removes an item from the dictionary and returns its associated value.
#poping key Area
print( Melbourne.pop('Area') )
#resulting dictionary after pop
print(Melbourne)
The dictionary.pop() call removed the key and returned the value of the item, whereas the next line prints the remaining dictionary which is now without Area.
9,993 sq.km
{'Population': '4,963,349', 2021: 'impacted by covid'}
Removing last item using .popitem()
dictionary.popitem() removes the last key-value paid added and returns it as a tuple.
#poping key Area
print(Melbourne.popitem())
#resulting dictionary after pop
print(Melbourne)
The first function removed the item and returned the key: value item in a tuple format. When we print the dictionary after .popitem(), we see that last items is no longer there.
(2021, 'impacted by covid')
{'Area': '9,993 sq.km', 'Population': '4,963,349'}
Loading data from kaggle directly into S3 is a two step process. In first step we configure Kaggle to be able to download. And in second step, we extract data from Kaggle into S3 bucket.
Get data from Kaggle
To get data from kaggle, we setup Kaggle command line tool and then generate an API token to get the data.
Setup Kaggle Command Line
To get data from Kaggle, we will install kaggle-cli.
pip install kaggle
Create API tokens
From top right, click on your account name and then click on Account
Account page has a panel for creating new Api token.

It will download kaggle.json which we can then use as a token. Move this file to Kaggle’s Environment folder. By default its in user’s home directory /.kaggle/
Download data on local
To demonstrate, I am using this dataset from Kaggle.
From the three dots on the right side, select the Copy API command.
[su_box title=”Copy data” style=”glass” radius=”1″]kaggle datasets download -d ajaypalsinghlo/world-happiness-report-2021[/su_box]
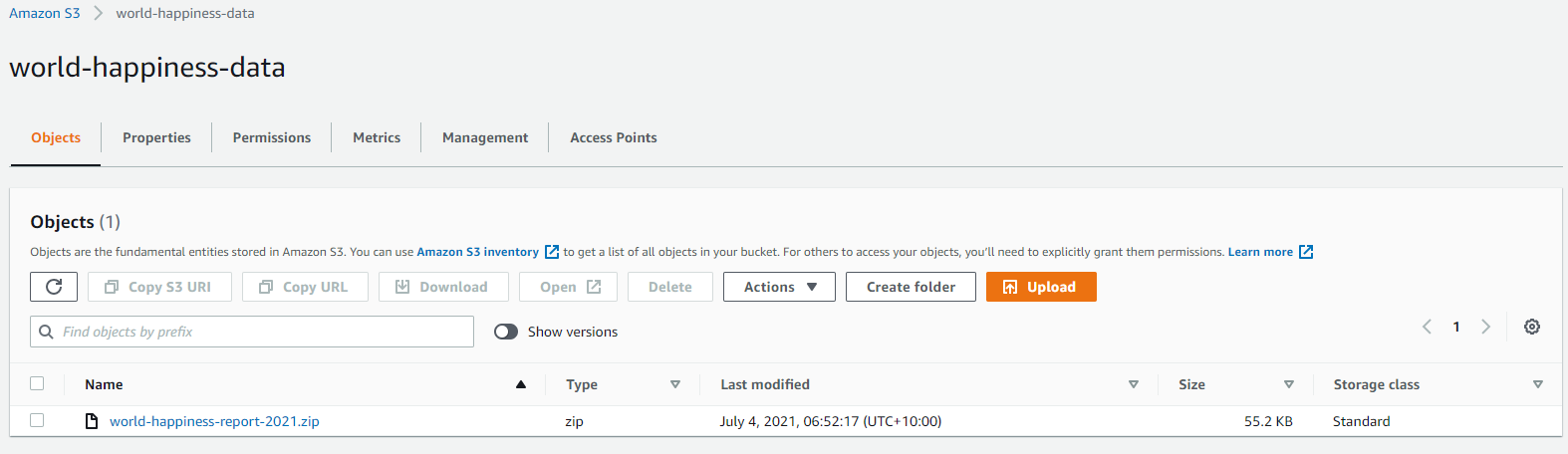
This will download the file on your local desktop.
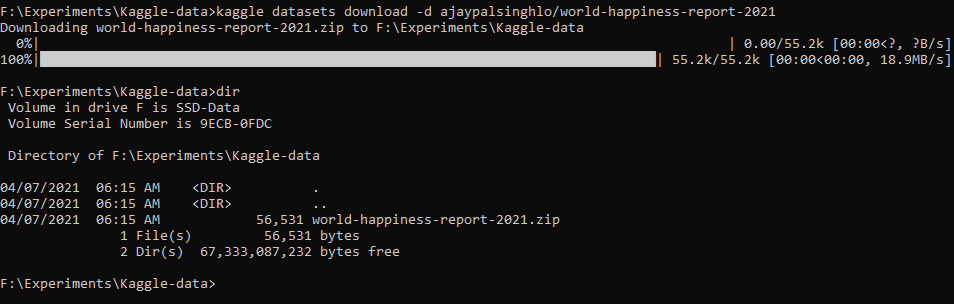
Copy data to S3
Setup AWS Command Line
To copy data from local desktop to AWS s3 bucket, AWS provides CLI tools. To use AWS CLI tools, we first need to generate aws access credentials. This can be done from AWS web console.
Generate S3 AWS secret
In the AWS S3 interface. Select IAM -> Users from services.
Click on Add User.
Check Programmatic access.
It will generate an access key id and secret access key.

Configure Keys in local system
To check AWS key configuration, type :
aws configure list
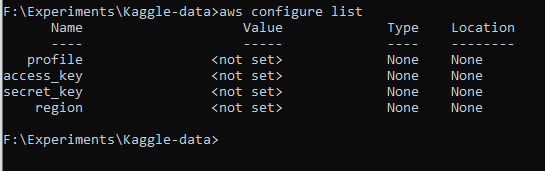
Use aws configure command to enter the key and secret from the previous step.

Succesful configuration will result in a configuration list that looks like the following :
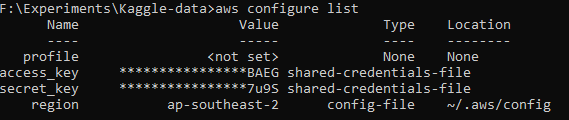
Create S3 Bucket
In the AWS console, select service S3 and click on Create Bucket.
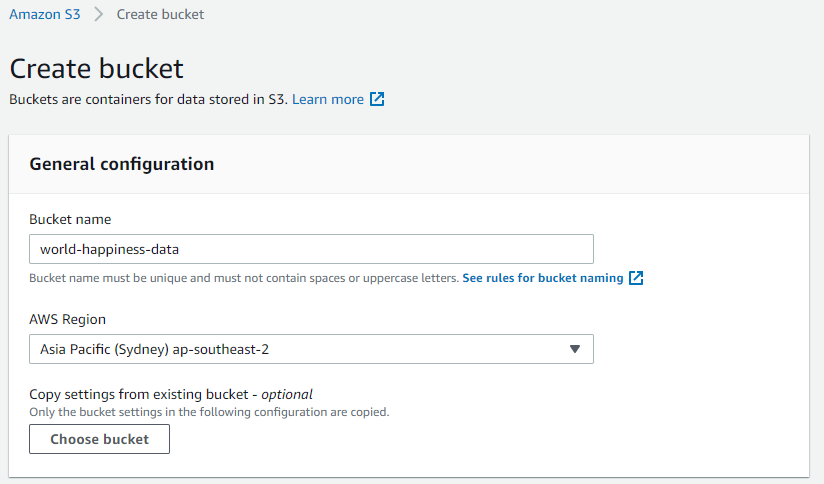
URI to access the bucket is not displayed in the console. However, it’s s3://bucket name. In our case, it will be s3://world-happiness-data
Copy data from local to S3
Now that bucket is created and our CLI is configured, we can run the copy command.
aws s3 cp world-happiness-report-2021.zip s3://world-happiness-data

verifying upload
We can verify the upload by going to Amazon AWS console > S3 > Bucket name