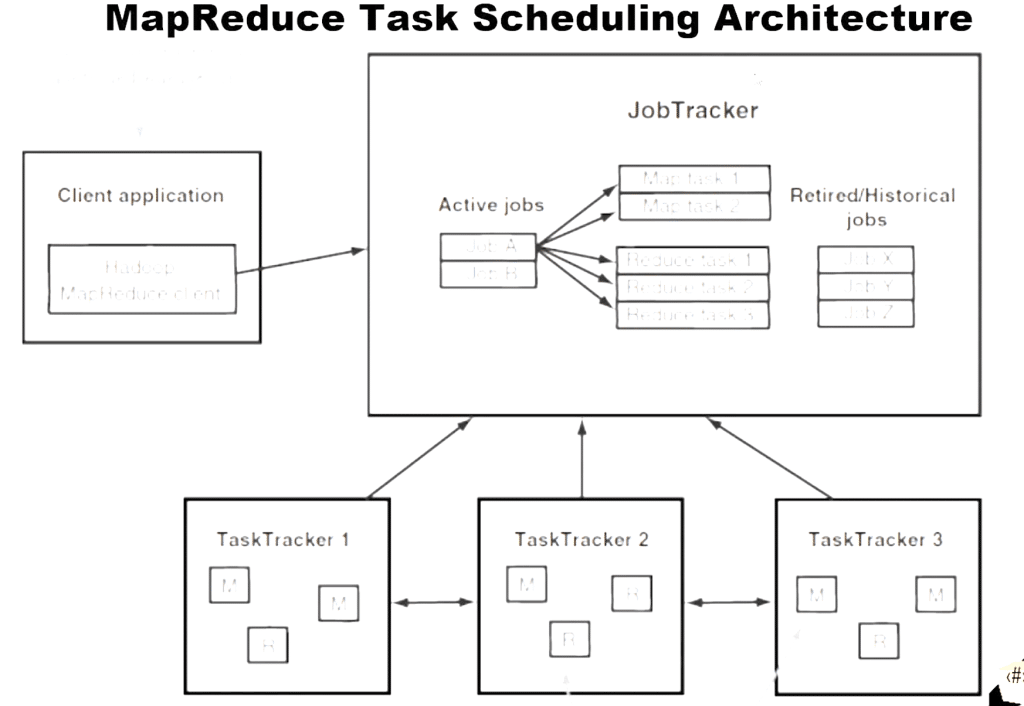
Here’s a simplified explanation of MapReduce task scheduling architecture:
graph TD
A["Client Job Submission"] --> B["JobTracker"]
B --> C["Resource Manager"]
C --> D1["TaskTracker 1"]
C --> D2["TaskTracker 2"]
C --> D3["TaskTracker n"]
D1 --> E1["Map Tasks"]
D1 --> F1["Reduce Tasks"]
D2 --> E2["Map Task (1 slot)"]
D2 --> F2["Reduce Tasks (2 slots)"]
D3 --> E3["Map Tasks"]
D3 --> F3["Reduce Tasks"]
%% Add descriptions
style B fill:#90EE90
style C fill:#FFB6C1
style D1 fill:#87CEEB
style D2 fill:#87CEEB
style D3 fill:#87CEEB
Key components:
- JobTracker: Central component that manages job scheduling and monitors progress
- Resource Manager: Handles resource allocation across the cluster
- TaskTrackers: Run on worker nodes, execute map and reduce tasks, and report status to JobTracker.
- Map Tasks: Process input data in parallel, creating key-value pairs
- Reduce Tasks: Aggregate and process mapped data to produce final output
This architecture enables distributed processing of large datasets across multiple nodes in a cluster, providing fault tolerance and scalability.