Data Build Tool ( DBT ) offers functionalities for testing our data models to ensure their reliability and accuracy. DBT tests help in achieveing these objectives .
Overall, dbt testing helps achieve these objectives:
- Improved Data Quality: By catching errors and inconsistencies early on, we prevent issues from propagating downstream to reports and dashboards.
- Reliable Data Pipelines: Tests ensure that our data transformations work as expected, reducing the risk of regressions when code is modified.
- Stronger Data Culture: A focus on testing instills a culture of data quality within organization.
This article is a continuation of previous hands-on implementation of DBT model. DIn this article, we will explore the concept of tests in DBT and how we can implement the tests.
Data Build Tool (DBT) provides a comprehensive test framework to ensure data quality and reliability. Here’s a summary of tests that dbt supports.
| Test Type | Subtype | Description | Usage | Implementation method |
|---|---|---|---|---|
| Generic Tests | Built-in | Pre-built or out-of-the-box tests for common data issues such as uniqueness, not-null, and referential integrity. | unique, not_null, relationships,accepted_values | schema.yml using tests: key under model/column |
| Custom Generic Tests | Custom tests written by users that can be applied to any column or model, similar to built-in tests but with custom logic. | Custom reusable tests with user-defined SQL logic. | 1. Dbt automatically picks up from tests/generic/test_name.sql starting with {% tests %} . 2. Schema.yml by defining tests in .sql file and applying in schema.yml 3.macros: Historically, this wa the only place they could be defined. | |
| Singular Tests | Designed to validate a single condition and are not intended to be reusable e.g. check if total sales reported in a period matches the sum of individual sales record. | Custom SQL conditions specific to a model or field. | Dbt automatically picks up test from tests/test_name.sql | |
| Source Freshness Tests | Tests that check the timeliness of the data in your sources by comparing the current timestamp with the last updated timestamp. | dbt source freshness to monitor data update intervals. | Schema.yml using freshness: key under source/table |
Implementing Built-In Tests
We will begin by writing generic tests. As we saw in the table above there are two types, Built-in and Custom. We will begin with a built-in test.
Built-in Tests 1.Unique :
We will explore this test with our model DEV.DIM_LISTING_CLEANSED.The objective is to make sure that all values in the column LISTING_ID are unique.
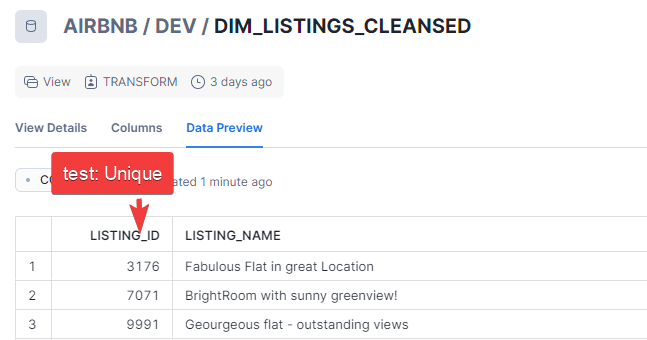
To implement tests we will create a new file schema.yml and define our tests in it.
version: 2
models:
- name: dim_listings_cleansed
columns:
- name: listing_id
tests:
- unique
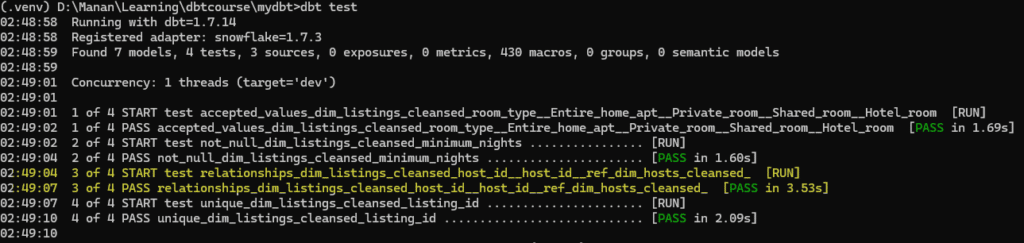
As we now run dbt test command in terminal, we will see the test execute and pass
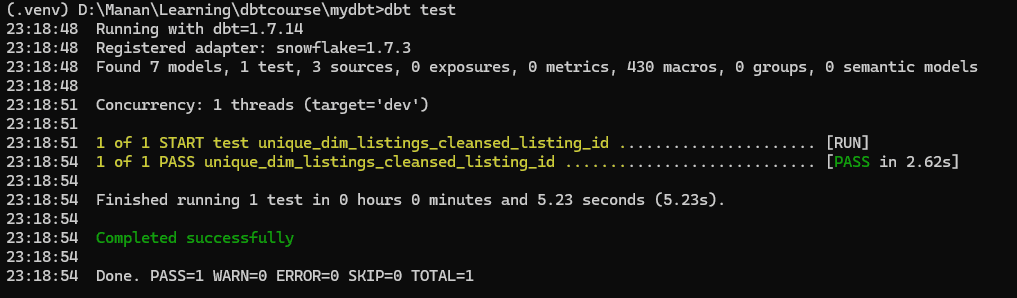
Built-in Test 2.not_null
In the not_null example, we do not want any of the values in minimum nights column to be null. We will add another column name and test under the same hierarchy.

- name: minimum_nights
tests:
- not_nullNow, when we execute dbt test, we will see another test added
Built-in Test 3. accepted_values
In the accepted_values test, we will ensure that the column ROOM_TYPE in DEV.DIM_LISTING_CLEANSED can have preselected values only.
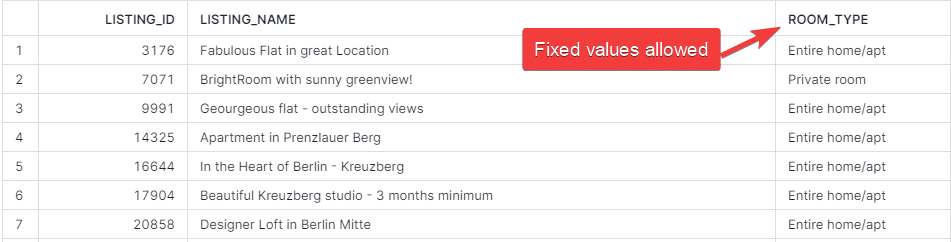
To add that test, we use the following entry in our source.yml file under model dim_listings_cleansed.
- name: room_type
tests:
- accepted_values:
values: ['Entire home/apt',
'Private room',
'Shared room',
'Hotel room']Now when we run dbt test, we can see another test executed which will check whether the column has only predetermined values as specificed in accepted_values or not.
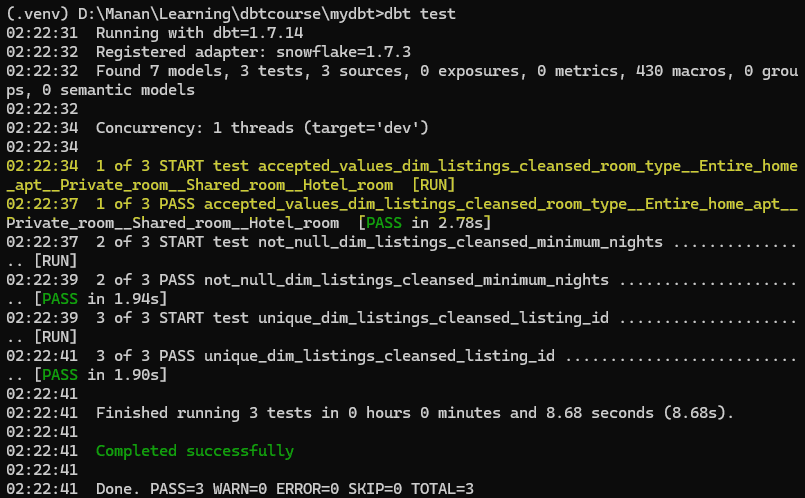
Built-in Test 4. relationships
In the relationships test, we will ensure that each id in HOST_ID in DEV.DIM_LISTING_CLEANSED has a reference in DEV.DIM_HOSTS_CLEANSED
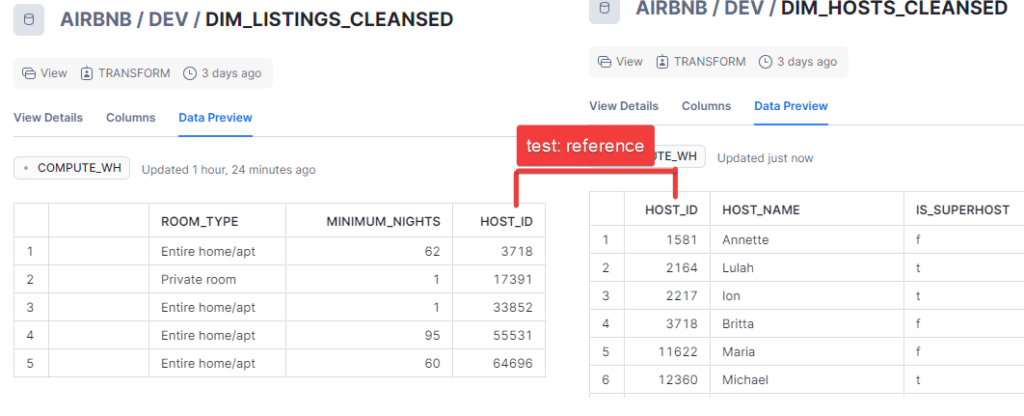
To implement this test, we can use the following code in our scehma.yml file. Since we are creating a reference relationship to dim_hosts_cleansed based on field host_id in that table. The entry will be :
- name: host_id
test:
-not_null
-relationships:
to: ref('dim_hosts_cleansed')
field: host_idNow when we run dbt test, we see the fourth test added.
Implementing Singular Tests
A singular test consists of an SQL query which passes when no rows are returns, or , the test fails if the query returns result. It is used to validate assumptions about data in a specificmodel. We implement singular tests by writing sql query in sql file in tests folder ,case dim_listings_minimum_night.sql
We will check in the test whether there are any minimum nights = 0 in the table. If there are none , result will return no rows and our test will pass.
Checking in snowflake itself , we get zero rows :
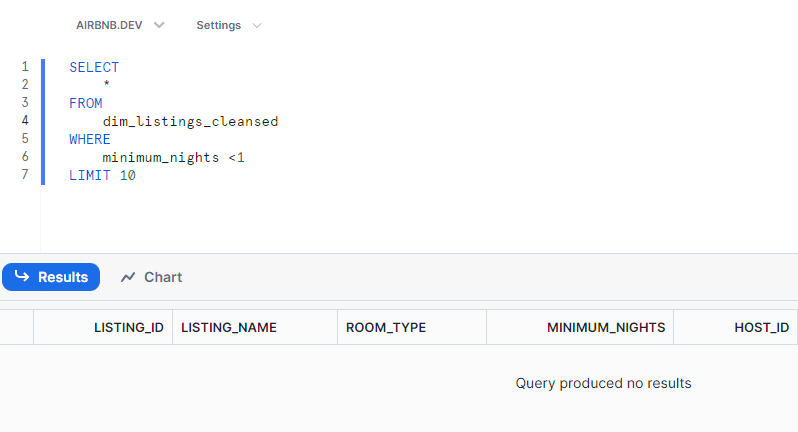
The test we have written in tests/dim_listings_minimum_nights.sql
-- tests/dim_listings_minimum_nights.sql
SELECT *
FROM {{ ref('dim_listings_cleansed') }}
WHERE minimum_nights <1
We can now implement the same test in dbt and run dbt test. In this case, I am executing a single test only. The output for which will become.
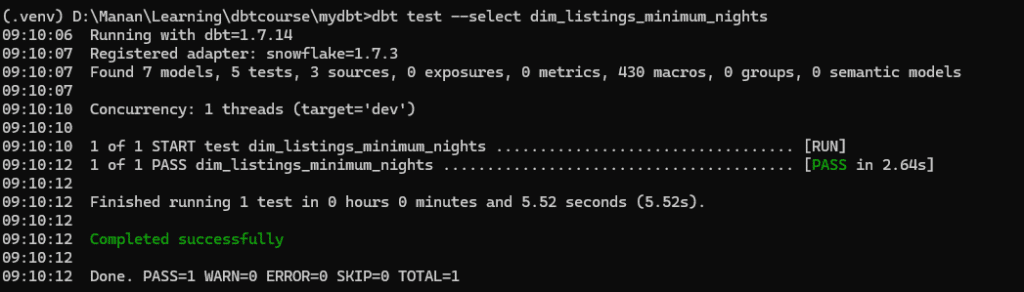
Since the resultset of the query was empty, therefore, the test passed. ( In other words, we were checking for exception, it did not occur, therefore test passed).
Implementing Custom Generic Tests
Custom Generic tests are tests which can accept parameters. They are defined in SQL file and are identified by parameter {% test %} at the beginning of the sql file. Lets write 2 tests using two different methods supported by DBT.
Custom Generic Test with Macros
First, we careate a .sql file under macros folder . In this case we are creating macros/positive_value.sql. The test accepts two parameters and then returns rows if the column name passed in parameters has value of less than 1.
{% test positive_value(model,column_name) %}
SELECT
*
FROM
{{model}}
WHERE
{{column_name}} < 1
{% endtest %}
After writing the test, we will specify the test within schema.yml file
To contrast the difference between Generic in-built test and Generic custom test, lets review the schema.yml configuration.
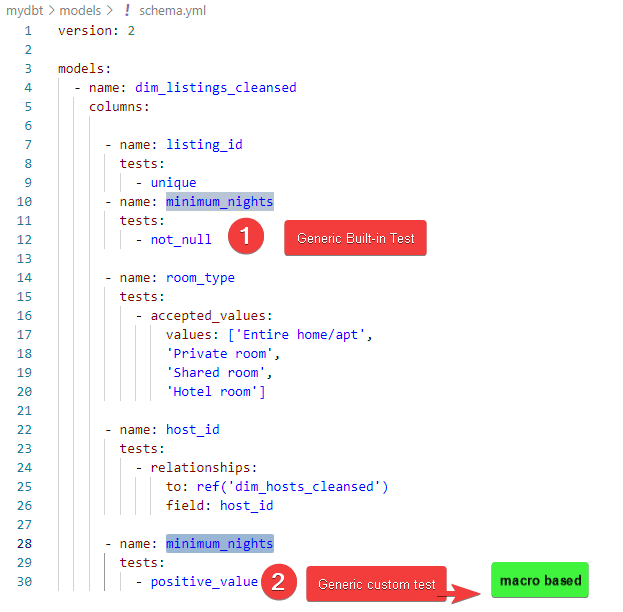
We have defined two tests on column minimum_nights. First was built-in not_null test that we did in last section. In this section, we created a macro by the name of positive_value(model,column_name) . The macro accepted two parameters. Both these parameters will be passed from schema.yml file . It will look up the model under which macro is specified and pass on that model. Similarly, it will pass on the column_name under which macro is mentioned.
Its important to remember that whether the test is defined in macros or is in-built. Test is passed only when no rows are returned. If any rows are returned, test will fail.
Custom Generic Test with generic subfolder
The other way of specifying custom generic test is under tests/generic. Also remember that we create a singular test under tests folder. Here’s a visual indication of the difference.

- Singular tests are saved under tests/
- Customer generic tests are saved under tests/generic
Since its a generic test, it will start with the {% test %} . The code for our test is
-- macros/tests/generic/non_negative_value.sql
{% test non_negative_value(model, column_name) %}
SELECT
*
FROM
{{ model }}
WHERE
{{ column_name }} < 0
{% endtest %}
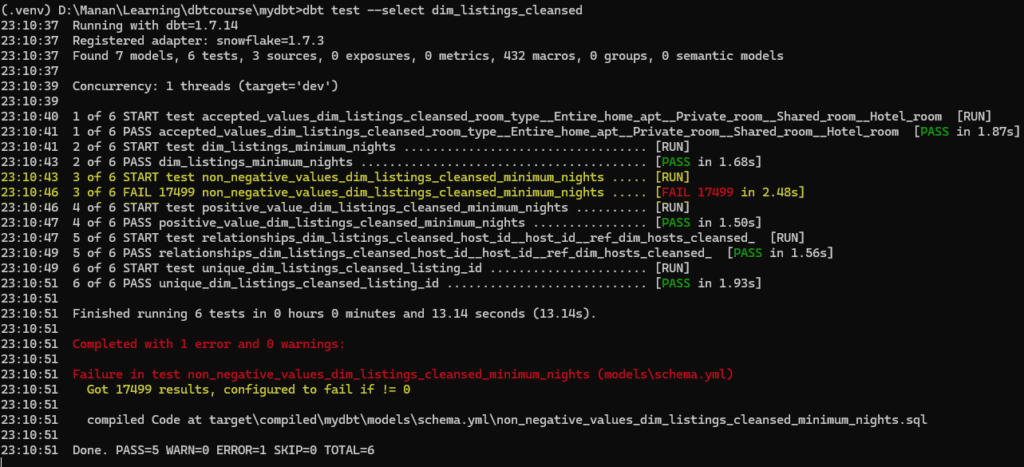
I want to implement this test on listing_id in dim_listings_cleansed. And I also want the test to fail. ( just to clarify the concept).I will go to schema.yml and define the test under column listing_id.
When I now run dbt test, DBT finds the test under macros/generic, however, it fails the test because there are several rows returned
Conclusion
In this hands-on exploration, we implemented various DBT testing methods to ensure data quality and reliability. We implemented built-in schema tests for core data properties, created reusable custom generic tests, and wrote singular tests for specific conditions. By leveraging these techniques, we can establish a robust testing strategy that safeguards our data warehouse, promotes high-quality data, and strengthens the foundation for reliable data pipelines.