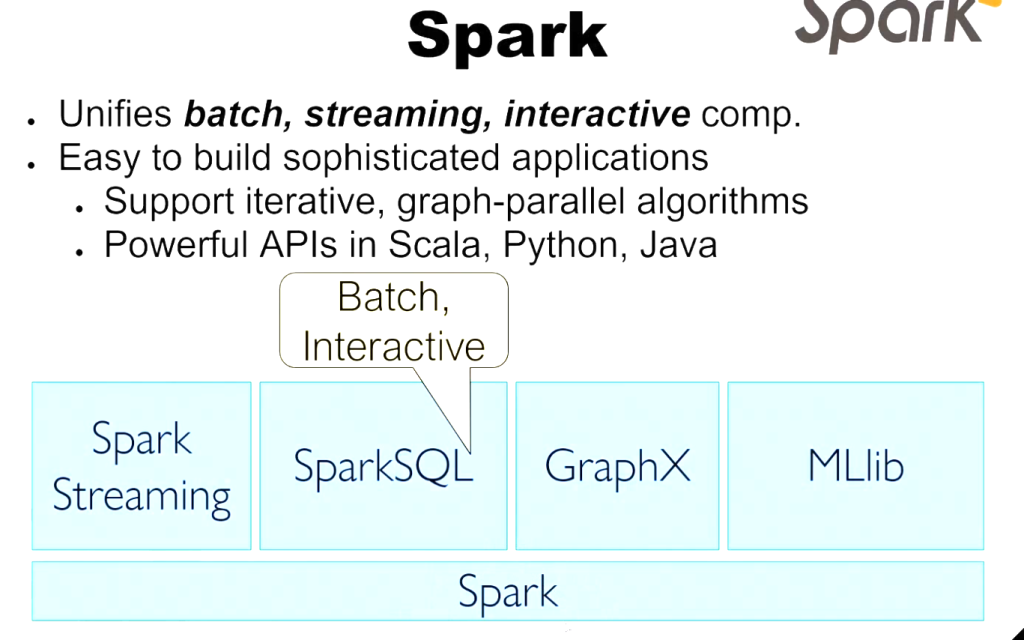
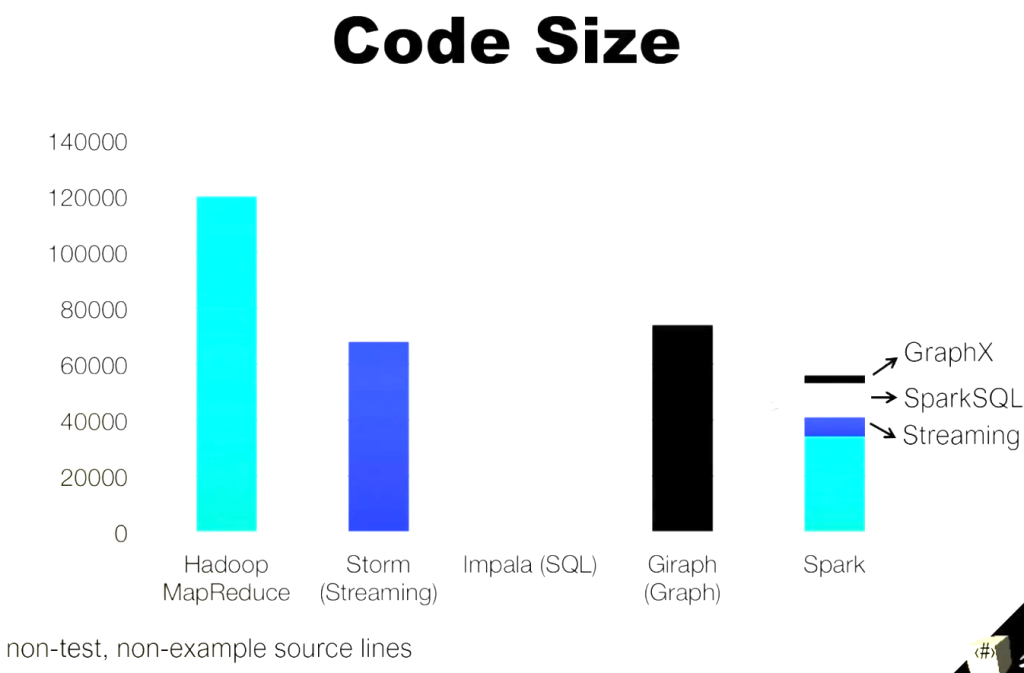
Motivation Behind Apache Spark
The limitations of MapReduce led to the development of Apache Spark, addressing key challenges in modern data processing.
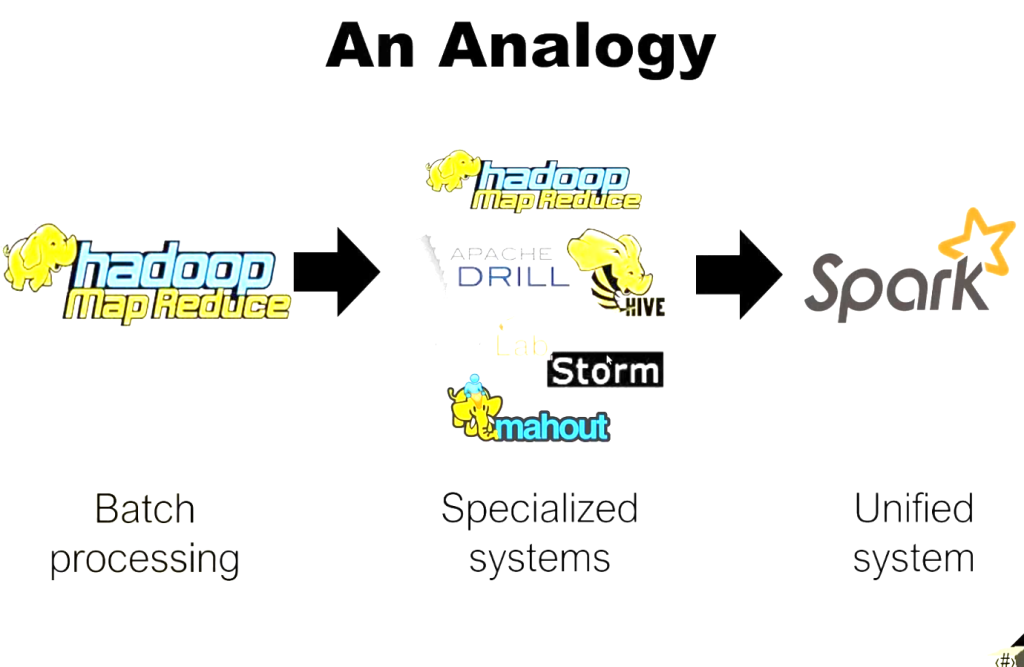
1.Distributed data processing began with Hadoop and MapReduce.
2.Over time, specialized solutions were built on Hadoop for streaming, SQL operations, and machine learning.
3.Finally, Apache unified these solutions to create Apache Spark.
MapReduce Limitations
- Disk-Based Processing: Every operation requires disk I/O, causing significant latency
- Two-Step Only: Limited to map and reduce operations
- Batch Processing Focus: Not suitable for interactive or real-time analysis
- Complex Implementation: Multi-step operations require multiple MapReduce jobs
Feature Comparison
| Feature | MapReduce | Spark |
| Processing Speed | Slower (disk-based) | 100x faster (in-memory) |
| Programming Model | Map and Reduce only | 80+ high-level operators |
| Real-time Processing | No ( through Storm only) | Yes (Spark Streaming API ) that is 2 to 5 times faster than Storm. |
| Machine Learning | No built-in support | MLlib library |
| Graph Processing | No built-in support ( Only supported via Pregel API ) | GraphX component which implements Pregel API in 20 lines of code |
| Interactive Analysis | No | Yes (Spark Shell) |
| SQL Support | Through Hive only | Native Spark SQL (includes Hive API and upto 100 times faster than Hive on MapReduce |
| Recovery Speed | Slow (checkpoint-based) | Fast (lineage-based) |
| Language Support | Java | Scala, Java, Python, R |
Key Spark Innovations
- Resilient Distributed Datasets (RDD): In-memory data structures for efficient processing
- DAG Execution Engine: Optimized workflow planning and execution
- Unified Platform: Single framework for diverse processing needs
- Rich Ecosystem: Integrated libraries for various use cases
These improvements make Spark a more versatile and efficient framework for modern big data processing requirements.
Spark Framework